10. Architecture
When discussing architectural patterns for the web, there is no one-size-fits-all type of solution. As we've learned in the previous chapters, we can have server-rendered web applications as well as web applications that live almost entirely on the client. Naturally, this will affect our architectural choices, at least to some degree.
Perhaps the most common architectural pattern for server-rendered web applications is the MVC pattern. This pattern divides the application into three components: Model, View, and Controller.
MVC pattern
The MVC pattern is quite common in GUI software. In there, the view component could communicate user interaction directly to the controller, which, of course, is not possible using HTTP.
The MVC pattern is most suitable for server-rendered web applications. If a lot of the logic is handeled on the client-side, the server architecture consist of the controller and the model, while the view is constructed on the client-side. This will most likely force the view component to take some of the roles of the controller.
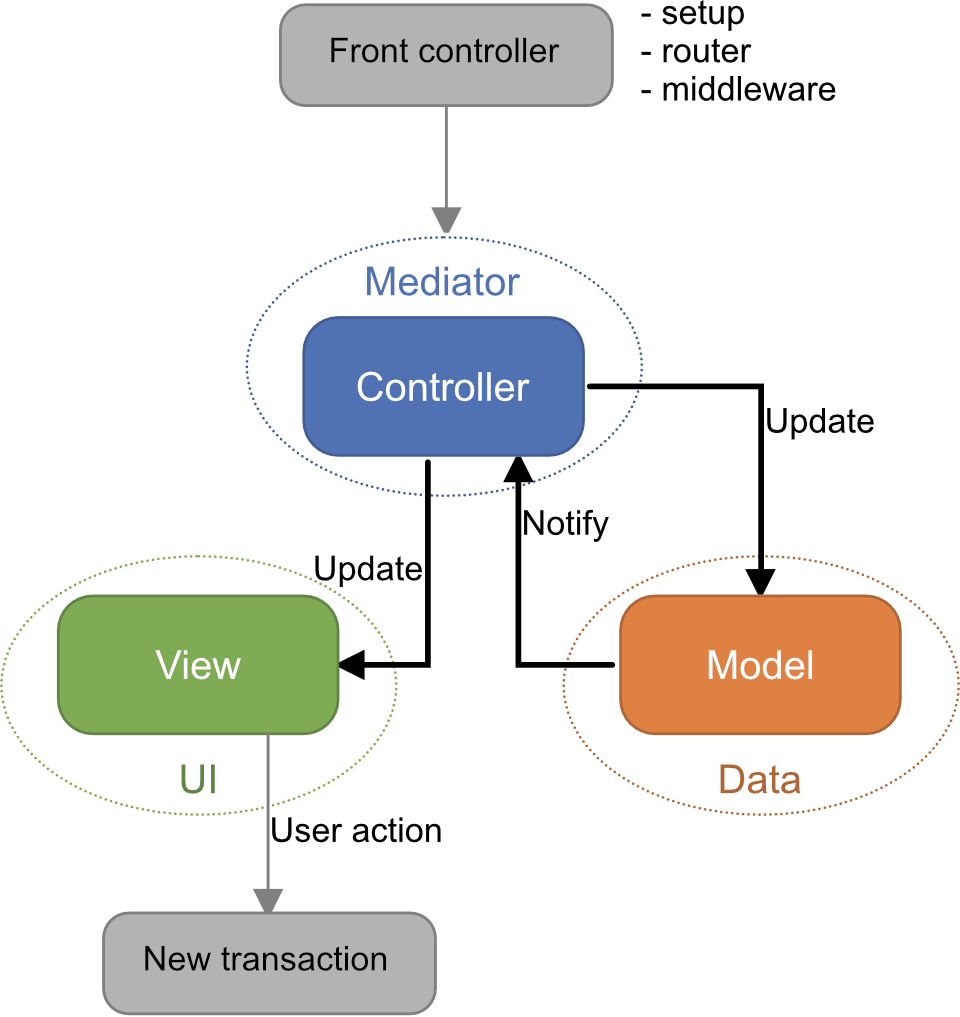
The model
We've already gotten pretty familiar with the model in the previous chapter, where we introduced the Mongoose ORM. Most MVC web frameworks will use some flavor of ORM that will fit nicely as the model of MVC.
If you were to write the model component on your own, you would probably want to write a model class that all application models inherit. This would hide the logic of data persistence and retrieval. Often this will mean an abstraction layer between a datastore and the business logic.
The model's main responsibility is then to manage the data. It stores and retrieves data from a database. Ideally, the model does not have any knowledge about what the application is used for or how the data is shown to the user. The model should be agnostic about moving the application from a web application to a desktop application.
The controller will send requests to the model for execution and the model will return data to the controller.
The view
In server-rendered web applications, the view is quite dumb. It will have elements in it that will result in changing the application state (such as links and forms), but it cannot directly communicate back to the application - when the view has been returned, the transaction has ended.
Most websites have common elements, such as a navigation bar and a footer section, that do not change a lot between pages. To avoid repeating the markup, most web frameworks will use some sort of templating engine. One feature of such is the ability to define a "master" layout with a "slot" for the changing content. Using Handlebars, for example, you might define a master layout such as this:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>My Website</title>
<link rel="stylesheet" href="css/main.css">
<script src="js/main.js"></script>
</head>
<body>
<header>
<nav>
<ul>
<li><a href="/index">Home</a></li>
<li><a href="/about">About us</a></li>
<li><a href="/contact">Contact</a></li>
</ul>
</nav>
</header>
<section>
<!-- Changing content area -->
{{{body}}}
</section>
<footer>
<p>Copyright © 2021 - My Website</p>
</footer>
</body>
</html>
The {{{body}}} statement defines the place where the changing content will be inserted. The triple brackets are reserved specifically to serve this purpose: loading templates into other templates. Now, the changing pages could be as simple as this (example using Handlebars template engine):
<h1>About us</h1>
<p>We are a small company passionated about brewing great coffee...</p>
So, the changing file contains only the content unique to that page.
Another feature of templating engines is injecting dynamic data into static HTML. Let's say we are creating a simple task application and that we want to list all todos from the database. The view could accept an array of todo items and inject their data onto the template (e.g., using the Handlebars templating engine):
<h1>All todos</h1>
{{#each todos}}
<h2>{{title}}</h2>
<p>{{content}}, created at {{created_at}}<br />
{{#if completed}}
<strong>Hooray, you've done it!</strong>
{{else}}
C'mon, get on it!
{{/if}}
</p>
{{/each}}
This file assumes data such as this:
let data = {
"todos": [
{
"title": "Go to the store",
"content": "You should go to the store to buy milk",
"created_at": "2021-12-02 10.36",
"completed": true
},
{
"title": "Buy milk",
"content": "Get the low-fat one",
"created_at": "2021-12-02 10.41",
"completed": false
}
]
};
Now, a web application like this today would most likely use a client-side JavaScript framework, such as React, Vue, or Angular to handle the rendering of the changing content. However, there are valid reasons to stick with server-rendered templates, too. We'll cover them later in this chapter.
There are courses specifically for creating web user interfaces, so I will only show a little bit of Vue.js code here. Just so that you can see the similarities in client-side rendering:
<div>
<div v-for="todo in todos" :key="todo.id">
<h2>{{todo.title}}</h2>
<p>{{todo.content}}, created at {{todo.created_at}}<br />
<strong v-if="todo.completed">Hooray, you've done it!</strong>
<span v-if="!todo.completed">C'mon, get on it!</span>
</p>
</div>
</div>
Of course, you can use Handlebars.js on the client-side just as you can use it in Node.js server, but most JavaScript web user interfaces are written with one of the three frameworks listed above.
The controller
When a request arrives, it is routed to a suitable controller in the MVC model.
The controller handles user interactions, validates data, checks for permissions, and orders the model to change state. It controls the application logic on a high level and reveals how the application works.
When getting to know how a foreign web application works, I usually start with the routes and then the controller in question. I should not need to know how the model implements its responsibilities, as long as it works the way the controller requests it to work.
The controllers are the "brains" of the application.
To recap:
| View | Controller | Model |
|---|---|---|
| Presents the UI. | Handles user interactions and manipulates the model. | Manages data. |
| Provides an interface for interacting with the system. | Controls the application logic on a higher level. | Stores and retrieves data from a database. |
| Often reflects the model of the application. | Reveals how the application works. | Has no knowledge of what the application is for. |
| Displays this information in a view-specific way. | The brains of the application. | Has no knowledge of how the data is shown to the user. |
| Only responsible for displaying info. | The controller can send a request to the model. | |
| However, may contain some application logic. | The model is responsible for executing that request. | |
| Receives updates from the controller about the model. |
Let's look at a sample web application architecture. This code shows the backend of a Todo application. It assumes use via an API, so the view is not shown here.
Warning
This code shows a simplified approach and is missing several key components.
// THE FRONT CONTROLLER
const http = require("http");
const handleRequest = require('./router');
const server = http.createServer(handleRequest);
server.listen(3000);
const TaskController = require('./controllers/TaskController');
// load some extra helpers
const { respondJSON } = require('./utils');
const handleRequest = async (request, response) => {
const { url, method } = request;
// match routes as delegate to suitable controller
if("GET" === method && "/api/todo" === url) {
TaskController.index(request, response);
} else if("GET" === method && url.match(/\/api\/todo\/([0-9]+)/)) {
TaskController.show(request, response);
} else if ("POST" === method && "/api/todo" === url) {
TaskController.store(request, response);
} else if ("PATCH" == method && url.match(/\/api\/todo\/([0-9]+)/)) {
TaskController.update(request, response);
} else if ("DELETE" === method && url.match(/\/api\/todo\/([0-9]+)/)) {
TaskController.delete(request, response);
} else if ("OPTIONS" == method) {
respondJSON(response, 200, {});
} else {
respondJSON(response, 404, { message:"Route not found" });
}
};
module.exports = handleRequest;
// THE CONTROLLER
const Task = require('../models/Task');
// load some helper functions
const { getRequestData, respondJSON } = require('../utils');
class TaskController {
// list all resources
static index(request, response) {
try {
const data = Task.all();
respondJSON(response, 200, data);
} catch (e) {
console.log(e);
respondJSON(response, 404, {message: e.message});
}
}
// show specified resource
static show(request, response) {
try {
const id = request.url.split("/")[3];
const data = Task.findOrFail(id);
respondJSON(response, 200, data);
} catch (e) {
console.log(e);
respondJSON(response, 404, {message: e.message});
}
}
// store a new resource
static async store(request, response) {
try {
const data = await getRequestData(request);
const taskObject = await JSON.parse(data);
const newTask = Task.store(taskObject);
respondJSON(response, 200, newTask);
} catch (e) {
console.log(e);
respondJSON(response, 404, {message: e.message});
}
}
// update an existing resource
static update(request, response) {
try {
const id = request.url.split("/")[3];
const data = Task.complete(id);
respondJSON(response, 200, data);
} catch (e) {
console.log(e);
respondJSON(response, 404, {message: e.message});
}
}
// delete a specified resource
static delete(request, response) {
try {
const id = request.url.split("/")[3];
const data = Task.delete(id);
respondJSON(response, 200, {message: data});
} catch (e) {
console.log(e);
respondJSON(response, 404, {message: e.message});
}
}
}
module.exports = TaskController;
// THE MODEL
// load JSON data
let data = require('./data');
class Task {
// return all instances
static all() {
return data;
}
// attempt to return a specified resource
static findOrFail(id) {
let todo = data.find((todo) => todo.id === parseInt(id));
if(!todo) {
throw new Error(`Todo with id ${id} not found`);
}
return todo;
}
// store a new resource
static store(todo) {
let newTodo = {
id: this.nextId(),
completed: false,
...todo,
};
data.push(newTodo);
return newTodo;
}
// update a specified resource,
// in this case the business logic is to complete a task
static complete(id) {
let todo = this.findOrFail(id);
todo.completed = true;
return todo;
}
// attempt to delete a specified resource
static delete(id) {
let todo = this.findOrFail(id);
data = data.filter(task => {
return task.id !== todo.id;
});
return `Successfully removed task with id ${id}`;
}
// helper method for assigning unique ids for resources
static nextId() {
let max = 1;
data.forEach(t => {
if(t.id > max) {
max = t.id;
}
});
return ++max;
}
}
module.exports = Task;
MVC evolution on the web
In the early days of the web applications were mostly server-side. The client requested updates via forms or links and these updates were displayed in the browser via a full-page refresh.
These days more of the logic is pushed to the client. Client stores some state and data (this is important for example in case of loosing network connectivity) and uses XMLHttpRequests to transmit data and request updates from the server, allowing for partial page updates. The view is dynamically constructed on the client-side (e.g., based on fetched JSON data).
These updates transform the traditional MVC towards more API-oriented patterns: often rather than MVC, we migh have models, controllers, and some dynamic view, that takes on some responsibilities from both the model and controller.
SPA
In a typical server-rendered web application, each page is generated as HTML on the server and returned to the client browser. Each page also has its own URL, that is used by the client to request that page. When the user clicks on a link or submits a form, the entire page loads.
However, many pages share elements: header, footer, navigation, sidebar, logo, etc. It is, therefore, wasteful to download these shared elements with every request. It also takes some time for the browser and the server to finish exchanging all of the information.
In SPA, or single-page application, when a link is clicked, JavaScript intercepts it, performs an XMLHttpRequest, and only updates the relevant portions of the page, while the rest of the DOM tree remains unaltered. When this update happens, there is no transition to another page.
With SPA, applications may load faster and will use less bandwidth. This can lead to an improved user experience, similar to a native app.
So, with SPA, there is an initial page load containing some HTML, CSS, and JavaScript. Thus far, it is similar to any website. It can be difficult to define exactly when some website is SPA, but Adam Silver defines SPA as applications that handle routing or navigation using client-side JavaScript. So, the deciding factor is that once the initial page load completes, JavaScript prevents the browser from communicating with the server and instead takes responsibility for the communication.
We are using JavaScript to do the very thing that browsers are made for and already do for free [...]
From server-rendered to SPA and back again
Pushing application logic to the client and having the client responsible for rendering the DOM with JavaScript can lead to a very sluggish user experience with cheaper client devices and/or slow network speeds. There has been a recent trend of moving from server-rendered to SPA and back again. Tools, such as Inertia.js, Livewire, Next.js, Remix.js, and many others try to find a balance between server-rendered and SPA, as well as with where the application logic should reside.
Perhaps the most important downside of SPA is SEO, or Search Engine Optimization. Search engines index sites to make them visible in searches. SPA is difficult to index since the pages are constructed on the client-side during execution. For many businesses, SEO is the most important thing. But for SaaS platforms, social networks, or closed communities, SEO doesn't matter.
It can be much more challenging to create secure applications if a lot of the authorization logic seeps to the client. Attackers have access to the source code and can easily figure out how your application is constructed. Special care needs to be placed on the initial page load - since all of the transferred data might not be displayed on the UI, it can give developers a false sense of security, while sensitive data could be part of the initial data download.
There's also other business logic that starts to drip onto the client. You would most likely want to do validation on the client-side to be able to provide instant validation feedback. But as you know, you cannot trust client-side validation and must validate the data on the back-end, as well. Then you will have to duplicate your validation logic and rules, and that can easily introduce bugs to your system - the back-end validating with different rules than the client, for example. Another aspect is routing.
There's a good blog post by Adam Silver of the many disadvantages of single-page applications. While I do not think all of the disadvantages listed there are all that major, many of them are well worth considering.
Static generation
Static generation is the process of transforming some markup, such as markdown, into HTML. So, instead of writing HTML, you write some other, simpler syntax and generate HTML from that.
Markdown is perhaps the most common form of markup used to generate HTML nowadays. It has an easy-to-learn syntax and does not require fancy editors. For example, this:
# Heading
Here's a [link](http://www.tuni.fi) and a list:
- one
- two
... compiles to this:
<h1>Heading</h1>
<p>Here's a <a href="http://www.tuni.fi">link</a> and a list:</p>
<ul>
<li>one</li>
<li>two</li>
</ul>
For example, all of this course material here is written in markdown and compiled using mkdocs.
| Extra: Wikipedia - Markdown
| Extra: List of static site generators
Static generation vs. server-rendering
It is recommended to use static generation whenever possible because your page can be built once and served using a CDN (Content Delivery Network) that is closest to the user. This makes it much faster than having the server or the client render the page on every request.
You can use static generation for many types of pages that do not need to contain dynamic, often updating data:
- Blog posts
- News articles
- Product details
- Documentation
- Teaching material
If it is possible to pre-render the content ahead of a user's request, you should do so.
However, static generation is not possible if your page contains dynamic content and data that changes between users. If the page content changes on every request, you have to render it per request. In that case, you can use server-rendering. It will be slower, but the result will be up-to-date. Of course, you can - and many web frameworks do - cache the server-rendered pages at least for a while, thus improving performance and lowering server processing needs.
Further, if you need to server-render the page, you can try to make it faster by moving the computation physically closer to the client. The process of edge computing aims to improve performance by moving computations as close to the user as possible. This will be covered in the next web architecture course.
Or, you can skip pre-rendering altogether and use client-side JavaScript to populate the page with the changing data. This reduces work from the server but increases it on the client. A flagship mobile phone with a 5G network plan and good network coverage will, however, then possibly result in a drastically different user experience than with an underpowered phone with bad reception.
SPA vs. MPA
A Multi-Page Application (MPA) is a website consisting of multiple HTML pages. Normally, these will be server-rendered. This means, that when you navigate to a new page, a new HTTP request is created by your browser requesting a new page of HTML from the server.
A Single-Page Application (SPA) is a website consisting of a singe JavaScript application that loads in the user's browser and then renderes HTML locally. This means, that when you navigate to a new page, a new HTTP request is created by your browser requesting data from the server, which is then injected onto the DOM.
In MPAs, most of your page's HTML is rendered on the server, while in SPAs, most of the HTML is rendered locally by running JavaScript in the browser. Due to the larger initial load and smaller subsequent loads, SPAs will consistently perform slower on first page load vs. an MPA, but may perform faster in subsequent page loads.
Most SPA frameworks will attempt to mitigate this performance problem by adding basic server rendering on the first page load. This is an improvement, but it introduces new complexity due to the fact that your website can now render in multiple ways and in multiple environments (server, browser). This also introduces a new “uncanny valley” problem where your site appears loaded (HTML) but is unresponsive since the application JavaScript logic is still loading in the background. - docs.astro.build
As a generalization, MPAs use server-rendering, while SPAs use client rendering. MPAs handle routing on the server, while SPAs handle routing on the client. And finally, MPAs manage state on the server, while SPAs manage state on the client. This especially makes SPAs the superior architecture for websites that dealt with complex, multi-page state management - for example, Facebook, GMail, etc., while MPAs can be the superior architecture for serving static pages fast.
This and method chaining
When talking about architecture, we should also say something about the architecture of the JavaScript code. There is an often-used feature in JavaScript that allows for method chaining.
Now, if a function is declared in the global scope, this refers to the window object:
function sayHello() {
console.log("Hello " + this.name);
}
sayHello(); // => Hello undefined
As there is no global variable named name, undefined is printed. If the global name is defined, its value will be used:
const name = "Boris";
function sayHello() {
console.log("Hello " + this.name);
}
// The keyword this is not necessary in this case,
// as a global variable name is found anyways
sayHello(); // => Hello Boris
In a conventional function, this refers to the global object window in frontend and global in backend code (i.e., Node.js). If a function is set as a method, this refers to the owner object. this can, however, be explicitly bound: call(), apply(), and bind() are the predefined methods of Function object that allow for setting this explicitly. Remeber, in JavaScript Function is an object - it can have its own methods.
Method chaining as design pattern
We can exploit the fluidity of this to "pipe" or method-chain. Let's look at an example of a fictional tool than compresses JavaScript and CSS and prepares files:
import Compiler from './compiler.js';
Compiler
.minifyJS()
.purgeUnusedCSS()
.optimizeImages(.75)
.copyFiles();
console.log("Done publishing files!");
// There's only one statement, even though it is
// split to multiple lines for easier readability
There are certain similarities between method chaining in JavaScript and function chaining in functional programming. In addition, fetch() uses similar "piping" techniques, that is, promise chaining with .then() and .catch().
With and without method chaining
To see what's happening with method chaining, let's look at the same code snippet and its use with and without method chaining.
Without method chaining:
class Student1 {
constructor() {
this.firstName = "first name not set";
this.lastName = "last name not set";
}
setFirstName(value) {
this.firstName = value;
}
setLastName(value) {
this.lastName = value;
}
}
let s1 = new Student();
s1.setFirstName("John");
s1.setLastName("Doe");
... and with method chaining:
class Student2 {
constructor() {
this.firstName = "first name not set";
this.lastName = "last name not set";
}
setFirstName(value) {
this.firstName = value;
return this;
}
setLastName(value) {
this.lastName = value;
return this;
}
}
let s2 = new Student()
.setFirstName("John")
.setLastName("Doe");
Extra Video: Into the wild
In this video, I'll go over the process of installing a virtual server and configuring it so, that I can have my Node.js application answering to actual HTTP requests.
This video includes paid services, but I do not want to advertise any specific service, as there are many available and the server configuration part is not that different across many of them.
Summary
This is the last chapter for this course. It may seem like we've covered a lot of topics, but the fact is, that we've barely scratced the surface. Web development is a fast-changing field, where new ideas come up frequently and some old ideas fade. Understanding HTTP, HTML, CSS, and JavaScript are safe bets for the foreseeable future, but be vary of relying too much on frameworks, as you may invest a lot of learning into one just to see it suddenly dissappear completely - this has happened to me several times already.
There's plenty more to learn, but you now have the basic skills to understand web as a platform and are ready to continue your journey to the world of web development.