6. Asynchronous JavaScript
In the last chapter, we discussed callback functions in synchronous methods.
We discussed also how JavaScript is both dynamically and loosely typed scripting language. It has prototypal inheritance but also classes built on top of that. Functions in JavaScript are first-class citizens, which means that functions are acceptable as variables and parameters. This in turn makes JavaScript prone to functional paradigm. Finally, JavaScript has a single-threaded, event-driven concurrency model which enables user-initiated events, network requests, dynamic content updates, UI rendering, multimedia, animations, etc. to be served concurrently.
In the first chapter, there was this example piece of code:
results = query('SELECT * FROM users');
doSomethign(results);
This code was used to illustrate the problem of synchronous programming - if one task takes a long time to complete, the other lines are put on hold. As a solution, we very briefly mentioned the use of callback functions:
query('SELECT * FROM users', function(error, results) {
if(error) throw error; // handle errors
doSomethign(results);
});
doSomethingEsleInTheMeanTime();
This allowed the application to not freeze if the query took a long time to complete. But now, the results and the errors land inside of the callback function and not on the next line, where they would land in synchronous programming. The doSomethingEsleInTheMeanTime(); function does not have access to the results and does not know, whether the query succeeded or not.
Asynchronous communication
Asynchronous communication might already be a familiar concept to you, but it is very common when we use the Internet to transmit messages. In synchronous communication, there is no delay. If Alice has a question, Alice can phone Bob. Bob then answers the question and Alice has the answer. In asynchronous communication, Alice once again has a question, but this time Alice sends Bob an email. Sometime later Bob send the answer back in another email and Alice has the answer. The difference is that Alice can do other things while waiting for the email.
In JavaScript, a command is run until the end. This model is referred to as run-to-completion. Since other things are on hold during its execution, costly commands will result in a deteriorated user experience. While one command is busy doing some heavy lifting, the single thread may be blocked. A very simple example of blocking in action only requires two lines:
alert("I'll block you!");
console.log("I won't print until you click away the alert");
To avoid blocking in a single-threaded system, you may split heavy commands into sub-programs or use fancy techniques such as currying. Or alternatively, you may move to asynchronous execution by using, for example:
- asynchronous versions of functions, both versions may be available, e.g.,
fs.readFileSync()vs.fs.readFile() - event emittance or message posting
- asynchronous callbacks such as
setTimeout()that moves the task to the task queue - promises (or
asyncandawait) that moves the task to the job queue - child processes, web workers, generators (out of scope of this course)
There are pros and cons to being single-threaded and event-driven.
| Pros | Cons |
|---|---|
| no threads, no tricky synchronization with semaphores, locks, mutexes | free synchronization and context are gone |
| no race conditions either, thus no deadlocks, livelocks, or starvation | more flexibility, but more responsibility (inversion of control) |
| shared state, more deterministic behavior | sync exceptions exist like alert() or sync XHR, a good practice is to avoid them |
| no overhead of copying shared resources or managing thread states on stack | fragmented code, control flow becomes obscured |
| ..including error management | |
| cannot fully exploit the power of multiple processors |
Event loop
The single thread runs something known as the event loop. The event loop is the main actor in the JavaScript concurrency model. It co-operates with the call stack that maintains call frames to keep track of the current context and executes the topmost command (last in, first out - LIFO).
Event loop moves tasks from queues to the call stack:
- sync commands in the order of execution order;
- async callbacks are first put on a queue, implying a delayed execution.
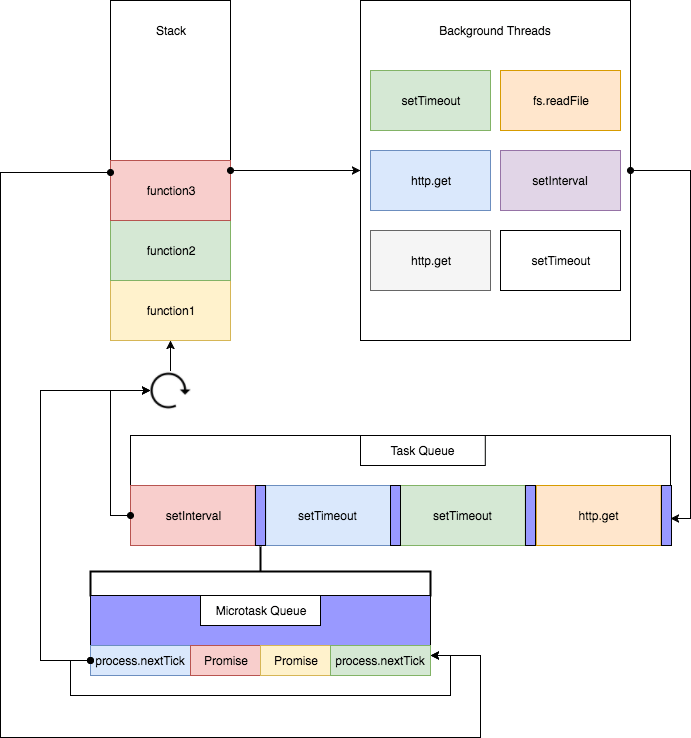
Macro- and micro-task queues
Asynchronous Web API calls are put in the task queue. These tasks are also called macro-tasks. APIs include event emitting, timeouts, and AJAX calls, etc. See the exhaustive list on the Mozilla Developer Network website.
| Extra: Mozilla Developer Network - Web API
In frontend side, these tasks coordinate browser components and have different priorities:
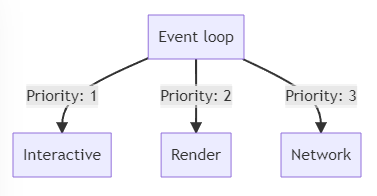
Jobs - or micro-tasks - do not interact with a browser but are dedicated to the use of the JS interpreter.
You can check the demo by Philip Roberts to better understand the event loop in action.
You may also run the demo on your own device, as long as you have a GitHub account.
git clone git@github.com:latentflip/loupe.git
cd loupe
npm install
npm start
firefox http://localhost:3051
Callback
A callback is a function passed as a parameter. Array functions, forEach(), map(), filter(), and reduce(), exploit callbacks synchronously; the callback function is called for each element in the array. Yet, being asynchronous exposes the full meaning of a callback as a function that is "called back" when its time has come: the desired event has been triggered (e.g., a user clicks something), a client gets server's response, or the JSON parser gets lengthy JSON message parsed, for instance.
In JavaScript, callbacks are often event handlers, set to the listen for a trigger, which explains why JavaScript is called event-driven: nothing happens without events.
So, callbacks are either synchronous or asynchronous. Run this example code to see the difference between synchronous callback (forEach()) and asynchronous callback (setTimeout()). alert() is used on purpose for blocking in synchronous mode.
A callback can be used as web API macro-tasks. They can be set to run after, for example
- user caused triggered event, such as
click,hover, etc - programmatically caused triggered event, also custom events
- network request being responded
- timeout
A timeout delays the execution even if time is set to zero. The following code:
function cb(time) { setTimeout(() => txt.value += (`cb${time}\n`), time) };
function cbTrigger(callback, time) { callback(time) };
txt.value += "before\n";
cbTrigger(cb, 1000);
cbTrigger(cb, 0);
txt.value += "after\n";
setTimeout(() => { txt.value=""; }, 5000);
... would result in the following execution order:
... immediately
prints before
prints after
prints cb0
... 1 second later
prints cb1000
... 5 seconds later
clears output
So, callbacks solve the issue. Are we done, then?
At the end of the last chapter, I went on a rant about some issues of callbacks. To illustrate them further (and to learn about an important technique), let's talk now about Ajax.
Network requests with Ajax
Up until now, we have made websites following the HTTP rule: one transaction = one request + one response. This has traditionally meant, that one transaction is loading one webpage, and clicking on links or posting forms loads a whole new page. Ajax can change that.
Ajax is short for Asynchronous JavaScript And XML, more officially known as the XMLHttpRequest or XHR for short. JSON has replaced XML as data format, but AJAX can be used to retrieve any type of data, not just JSON or XML. Ajax supports protocols other than HTTP, including file and ftp.
In essence, Ajax allows a browser to send and receive data in the background without loading the whole page. The major benefits are that:
- the users can still use the page whilst data is being exchanged
- after a response is retrieved, only the necessary parts of the page (DOM) will be rendered. This is much faster than loading an entire HTML page.
Ajax has been around for a long time, but it was only relatively recently that the web started to evolve towards this situation, where a website can transfer data while the page is open without reloading the page. Imagine a site like Facebook: you can click on "show more comments" which will load more data from the server and you can post new posts without refreshing the page. And you can chat, in which case you can post data to the server, but at the same time, there is some system that allows the other person's message to be pushed to your DOM without you initializing any event.
| Extra: Mozilla Developer Network - XMLHttpRequest
Ajax also exemplifies the asynchronous evolution: first callback, then Promise, followed by async/await and optimization with Promise.all(), with independent fetches.
Ajax with XMLHttpRequest (XHR) and a callback
Browser-server communication that happens "behind-the-scenes":
- XMLHttpRequestObject is created
- request is made using that object
- data is sent/fetched from the server
- XMLHttpRequestObject receives a response
- it fires a ready event
- event handler handles the response. For example, DOM is rendered dynamically, or a table is filled with data, etc.
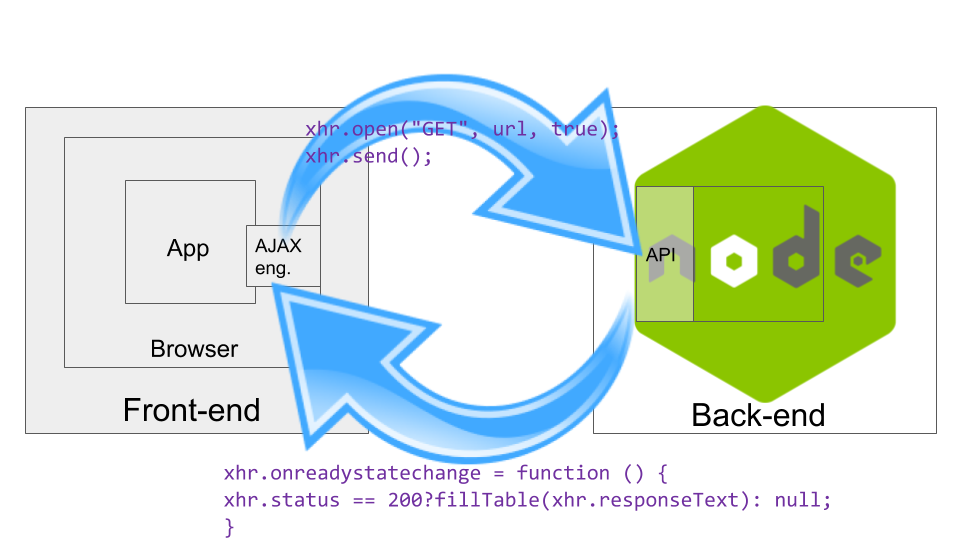
Nowadays XMLHttpRequests have been largely replaced with Promise-based fetch() function.
Let's, however, go through an XHR example in a bit more detail. First, an XHR object is created:
const xhr = new XMLHttpRequest();
... that provides onreadystatechange event handler triggered on state changes:
xhr.onreadystatechange = handlerFunction;
Then, a connection to a server is opened for sending the request:
xhr.open('GET', URL, true);
xhr.send();
HTTP methods GET, POST, and also PUT, DELETE, HEAD, and OPTIONS are allowed. URL here provides the HTTP address of the server. The third parameter, the boolean value, defines whether the request is handled asynchronously (defaults to true). For example:
const xhr = new XMLHttpRequest();
xhr.onreadystatechange = function () {
// the transfer complete
if (xhr.readyState == 4) {
// the transfer successful
if (xhr.status == 200) {
// the transferred data handled here
fillTable(xhr.responseText);
} else {
// handle the error
// error text in the property xhr.statusText
}
}
}
xhr.open("GET", url, true);
xhr.send();
This example uses a callback function (fillTable()) to alter the DOM once the data has been obtained. There is, however, a clear drawback to using callback functions with XHR: with nested callbacks, the situation quickly ends up a "callback hell" or "pyramid of doom".
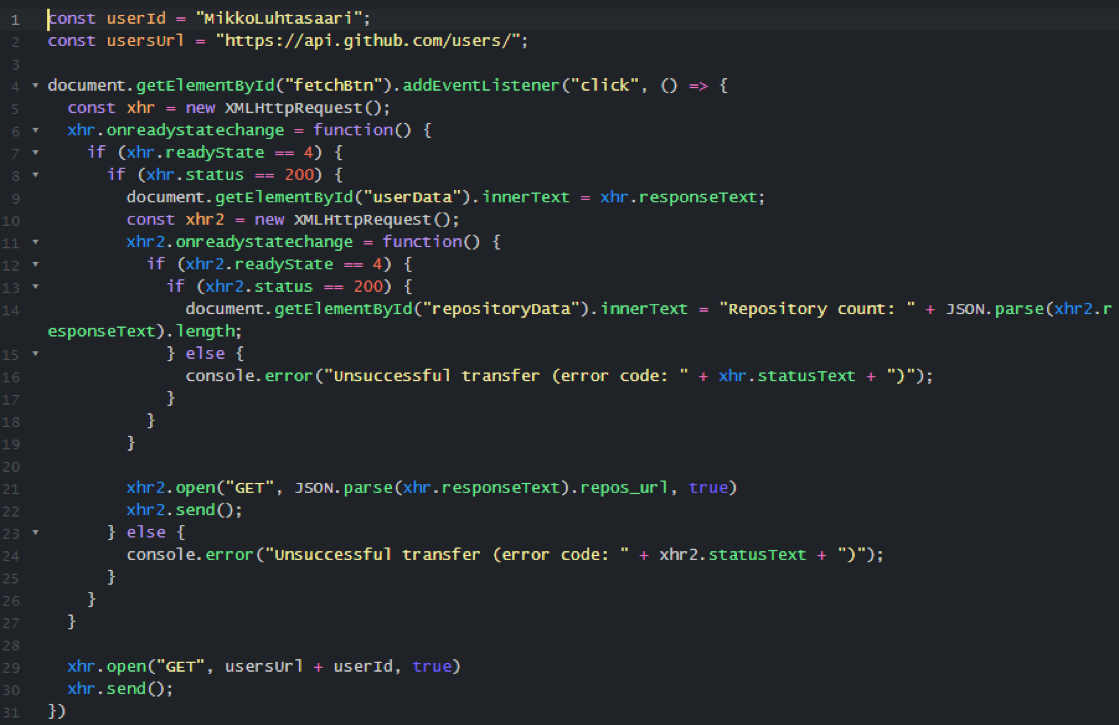
In the example, user and user repositories are retrieved from GitHub. Imagine what the example would look like with 5 nested callbacks. Let's say you made a request that resulted in a list of cities. Now, you would like to make a request for each city to get the weather forecast for that city. You would have to make that request inside the callback, because that is the place where the results of the previous XHR request are available. Then add three more.
Even if you can somehow handle all of these nested callbacks, what if one of the requests fails? So, the big issues with callbacks are that:
- nested calls require nested callbacks; pyramid of doom
- results and errors land inside callbacks, not on the next line, as with synchronous code
Promise
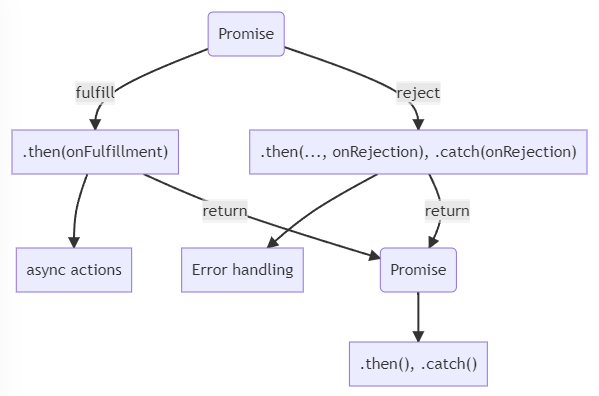
Promises can rescue us from the pyramid of doom. A promise represents an asynchronous result that is completed eventually. It is a promise given right now that the call will eventually resolve, successfully or not. Promises were added in ES2016.
Before a Promise is settled, it is in a pending state. Then, when the result is got, pending Promise moves either to:
- fulfilled state, i.e., it is successfully resolved. The promise may move to the next
then()function. - rejected state, Promise jumps either to the reject section of next
then()or tocatch()
In addition to then() and catch(), finally() is available as the completing last action for both branches.
You can make your function return a promise if the function can possibly take a long time to complete:
function wait(duration) {
return new Promise((resolve, reject) => {
// if the duration is negative, reject the promise immediately
if(duration < 0) {
reject(new Error("Time travel not implemented yet exception"));
}
// resolve the promise when the wait is over
setTimeout(resolve, duration);
});
}
Let's look at a common example scenario: Mom is happy and promises to buy a new phone. She goes shopping, so the promise is pending. A new phone was bought, technically fulfilling the promise, however still in the midst of "eventual completion" because to get it in use, a protection glass is then needed and a SIM card has then to be bought as well. After all these, the promise is fulfilled.
const isMomHappy = true;
// Promise
const willIGetNewPhone = new Promise(
function (resolve, reject) {
isMomHappy ?
resolve({ brand: 'Jolla', color: 'yellow' }) :
reject(new Error('mom is not happy'));
}
);
willIGetNewPhone
.then(data => {
data["accessories"] = ["protection-glass"];
return Promise.resolve(data);
})
.then(data => {
data["sim-card"] = true;
return Promise.resolve(data);
})
.then(data => console.log(data))
.catch(err => console.log(err));
So, what has changed with Promises? We got rid of the "pyramid of doom", the nested callbacks. We can now write multiple XHR requests in chain, for example. We can also run arbitrary number of Promises is parallel by using the Promise.all().
Promise API
The promise API has several methods, not just the aforementioned:
// the methods of moving from pending to settled
Promise.resolve() //"happy" path, Promise is fulfilled
Promise.reject() //"sad" path, Promise is rejected
// the methods that determine what happens to a Promise after settling
Promise.prototype.then() //the next phase after a resolved promise, returns a promise
Promise.prototype.catch() //catches any error (reject) of the promise chain
Promise.prototype.finally() //final actions at the end of the chain
// multiple promises taken as a param
Promise.all() //resolves promises concurrently, if any rejects, all() rejects
Promise.allSettled() //like reject-permissive all(), resolves when all are settled
Promise.any() //returns the first fulfilled promise of an arr
Promise.race() //like reject-permissive any()
So, Promises are Thenable. But what are Thenables?
Thenables
Thenable serves as a simplified executor that may be reused in resolve situations. At minimum, thenables implement the then() method. For example:
const thenable = {
then: function (onFulfilled) {
setTimeout(() => onFulfilled("it is fulfilled"), 10);
}
};
Promise.resolve(thenable)
.then(data => console.log(data));
// Or
Promise.resolve()
.then(data => thenable)
.then(t => console.log(t));
Every Promise is Thenable, but Thenable is not necessarily a Promise. Yet, they are easily "promisifiable":
const changedAsPromise = Promise.resolve(thenable);
Fetch(), Ajax call that returns a Promise
fetch() is quite well supported across browsers, but for use in Node.js you need to install it first:
npm install node-fetch
Then you can start fetching data:
const fetch = require('node-fetch');
const url = "http://lissu-api.herokuapp.com/";
const prom = fetch(url);
console.log(prom); //1
const thenProm = prom.then(response => response.json())
.then(data => console.log(data)); //3
console.log(thenProm); //2
// Promise { <pending> }
// Promise { <pending> }
// { vehicles:[ { id: '130792', line: '50B', ...
The execution of the program is straightforward, except promises, which are put in the queue of micro-tasks implying a delayed execution. The first and second console.log() print the promise as pending. After the call stack is empty, the event loop starts handling the promise:
fetch()returns a Promise that resolves as an HTTP Response.- Response implements Body which has json() method that returns JSON as a new Promise
- Once this Promise resolves, the JSON data is printed (the last output line in the example)
| Extra: Mozille Developer Network - Body (JSON)
Video: Test your skills with fetch and DOM manipulation
Async / Await
Promises rescued us from the pyramid of doom and made many things about asynchronous operations easier. But we still have the issue of results and errors landing somewhere else than on the next line, where they would be the easiest to work with. In ES2017 we got a long await ed solution to async hronous programming: the async and await keywords.
They work with Promises and make asynchronous operations look like synchronous operations. Both keywords need to be used together: if a function contains an await keyword, it needs to be made an async function.
The async keyword can be used in a function declaration or expression:
// declaration:
async function foo() {}
// expression:
const bar = async () => {}
// Both are promises
console.log(foo() instanceof Promise, bar() instanceof Promise)
Other than the async keyword, a function may look normal, but it is anticipated to be a slowpoke and to return a Promise either explicitly or implicitly: even if a plain value is returned, it will be wrapped inside a Promise.
Let's take another look at that imaginary situation of fetching cities and then fetching the weather forecasts for those cities from the beginning of this chapter.
let response = await fetch('/api/cities');
let data = await response.json();
data.cities.forEach(city => {
let weather = await fetch('/api/weater?city=' + city);
});
Easy, right? So, why not just use async / await, why waste time talking about callbacks and Promises first? Well, async functions return Promises, so you still need to understand Promises. And callbacks are so in the DNA of JavaScript, that there really is no avoiding them, either.
Adding async causes a chain reaction: its caller must be made async, and so forth; the chain ends at the main level. Alternatively, the async part may be isolated to its own block.
| Extra: Mozilla Developer Network - async function
| Extra: Alligator.io - async function
One means to have an async block is to use IIFE, or Immediately Invoked Function Expression.
The simplest IIFEs need neither name nor arguments. For example:
(async () => {
const res = await Promise.resolve("Go, IIFE, Go!");
console.log(res); // prints Go, IIFE, Go!
})();
As we have learned in the last chapter, having parentheses around a function declaration converts it as an expression. The expression is self-invoked by the last trailing parentheses.
In addition to the keyword async, async functions can be instantiated with AsyncFunction:
new AsyncFunction([arg1[, arg2[, ...argN]],] functionBody)
For example:
const AsyncFunction = Object.getPrototypeOf(async function() {}).constructor;
function createAsync() {
return new AsyncFunction('a', `return new Promise((resolve) => {
setTimeout(() => {resolve(a)}, 1000)
});`);
}
createAsync()("WebDev1").then(data => console.log(data));
(async function myFunction() {
const res = await createAsync()(1);
console.log(res);
})();
The constructor enables also async testing:
const isAsync = myFunction.constructor.name === "AsyncFunction";
await waits for the resolution of a Promise and pauses the execution until that.
async function may or may not contain an await statement, but await statement must reside inside an async block. Otherwise:
await Promise.resolve("yes!")
^^^^^
SyntaxError: await is only valid in async function
To sum up, async and await are implemented as syntactic sugar on top of Promises.
An await causes an async function to pause until a Promise is settled. Thus, async / await resembles synchronous mode but is less prone to blocking.
Let's refactor fetch() with async / await. Below, the value of the first await expression is that of the resolved response, and the second, the parsed JSON. Parsing may take time.
const fetch = require('node-fetch');
const url ='https://jsonplaceholder.typicode.com/todos/1';
(async () => { //as IIFE
let response = await fetch(url); //the 1st
let parsed = await response.json(); //the 2nd
console.log(parsed);
})();
Promises rescued us from the pyramid of doom and async / await allowed the results and errors to land on the next line. We can now write code that appears like synchronous code but has (some of) the benefits of asynchronous code. I say some of, since we have now introduced an issue: unnecessary sequential requests.
Promise.all()
Suppose that we've written an async function that fetches JSON from some API:
async function getJSON(url) {
let response = await fetch(url);
let body = await response.json();
return body;
}
And now we want to fetch JSON from two different endpoints:
let data1 = await getJSON(url1);
let data2 = await getJSON(url2);
The problem with this code is that it is unnecessarily sequential: the second fetch will not begin before the first one completes. As the second fetch does not depend on the results of the first fetch, there is no need to execute the two opeations in sequence and waste time.
In order to await a set of concurrelty executing async functions, we can use the Promise.all().
Promise.all() starts multiple Promises in parallel and waits for them all to finish. After all the Promises are fulfilled, it returns a single Promise, that contains resolved values as an array. For example:
const proms = [1, 2, 3].map(val => Promise.resolve(val));
Promise.all(proms)
.then(res => console.log(res, typeof res, Array.isArray(res)));
// Array [1, 2, 3] 'object' true
However, Promise.all() rejects if any of the Promises rejects.
Now, we can refactor the two sequential calls to getJSON() with Promise.all() to happen concurrently:
let [data1, data2] = await Promise.all([getJSON(url1), getJSON(url2)]);
| Extra: Mozilla Developer Network - Promise.all()
Time consumption of await calls inside async block is got as a sum. Promise.all() makes the calls concurrently, thus the time approaches the time spent by the longest call.
Fetch() example with Promise.all()
Here, fetching and JSON parsing are done in parallel. First, an iterable of Promises (prom1 and prom2) is passed as an input parameter.
const fetch = require('node-fetch');
const url1 = 'https://jsonplaceholder.typicode.com/todos/1';
const url2 = 'http://lissu-api.herokuapp.com/';
const prom1 = fetch(url1);
const prom2 = fetch(url2);
Promise.all([prom1, prom2])
.then(response => {
Promise.all([response[0].json(), response[1].json()])
.then(parsed =>
parsed.forEach(json => console.log(JSON.stringify(json))));
});
The iterable is returned as a resolved value: response array. The next Promise.all() takes another array of Promises, this time the return values of Body.json() calls. The innermost then() prints the resolved values.
Sidenote: async implementation details
The contents of this sidenote are not important for web developers, but if you want to understand async function implementation, we can take a quick look.
Imagine you have a simple async function like this:
async function f(x) { /* ... */ }
This is sort of a Promise-returning function wrapped around the body of your original function:
function f(x) {
return new Promise(function(resolve, reject) {
try {
resolve((function(x) { /* ... */ })(x));
} catch (e) {
reject(e);
}
});
}
Async enablers
Like we've read many times by now, functions are first-class citizens in JavaScript. This enables functional coding style. This also enables passing functions as arguments, setting them as variables, or as return values. Remember the difference in representation:
function declaration:
function add(a, b) {
return a + b;
}
... and function expression:
const addAnon = (a, b) => a + b;
Functions can be invoked by its name or assigned variable. There is, however, an important practical difference: hoisting. As was discussed in the last chapter, JavaScript hoists declarations, but not initializations. Because of this, function expressions can lead to ReferenceError if called before the expression. So, this example is perfectly OK because of hoisting:
add(1, 2);
// This will be hoisted to the top
function add(a, b) {
return a + b;
}
... but this will cause a ReferenceError:
addAnon(1, 2);
// This will only be defined once the interpreter reaches here
const addAnon = (a, b) => a + b;
As discussed before, functions are invoked with parentheses. We can pass functions around as parameters and invoke them when we want to by just adding the parentheses:
function invokeAdd(a, b) {
return a() + b();
}
function one() {
return 1;
}
function two() {
return 2;
}
const answer = invokeAdd(one, two);
In this example, one and two are bound to formal parameters a and b and a() and b() are invoked with parentheses.
AS IIFE (discussed in section async / await), anonymous functions are declared and executed in one go:
console.log("sum = ", ((a = 1, b = 2) => a + b)());
Closures
A closure implies a lexically-scoped name binding: a closure stores a function together with its environment, including parameters and variables. In JavaScript, lexical scoping is defined by the function's scope: each function creates a new scope.
Closures enable encapsulation and variable scoping (you know, the private and public seen in other programming languages), thus fostering, e.g., the implementation of objects.
An inner function sees the outer-function variables, but not the other way around:
const d = 7;
((a = 1, B = 2) => {
const c = a + b + d;
// c is defined here and can be used
console.log("closure sum = ", c);
})();
// ReferenceError: c is not defined
console.log(c);
So, closures can be used to achieve similar behavior that private and public keywords achieve in other languages. There is a specificity rule: variables are searched in the descending order of specificity, first the closest scope.
Closures can be used to create scopes. As discussed in the previous chapter, JavaScript has three scope levels, the block scope, the function scope, and global scope. In any large software placing all the required variables in the global scope is obviously a really bad idea. Scopes can be used to remedy this and closures can be used to create scopes. Here's an example from Mozilla Developer Network:
const makeCounter = function() {
let privateCounter = 0;
function chageBy(val) {
privateCounter += val;
}
return {
increment: () => changeBy(1),
decrement: () => changeBy(-1),
value: () => privateCounter
};
};
const counter = makeCounter();
counter.increment();
In the example, the privateCounter is "private" because it is in the function scope. The function changeBy() can access the privateCounter because they share the same scope. To the outside world we expose the methods increment(), decrement(), and value(). An inner function or a callback is also a closure in the context of a containing function.
Video: Build a Todo app
In this multi-part video series, we'll go over how to implement a simple, yet functional web application. While it may seem like this application is super simple, it still covers a great deal of the basics we are focusing on in this course, such as different headers, request methods, routing, CORS, and more.
Part 1 - starting the Node.js server
Part 2 - completing the API routes
Part 3 - architectural improvements
Summary
Use async/await to write asynchronous code.
... but be aware that many libraries still rely on callbacks.
async/await are just syntactic sugar on top of Promise, but when approaching JavaScript from some other language, they might make promises easier to take in. And when you can make multiple asynchronous operations simultaneously, you should do so. Don't wait for one request to complete before making another one, unless you have to.