2. HTTP, Client-server
HTTP - how content gets around
HTTP stands for HyperText Transfer Protocol. It is an application level protocol on the 8th level of the OSI model. It is the foundation of any data exchange on the Web. It is a client-server protocol, meaning that we have some client initiating requests for some server. Usually, this client, known as the user-agent, is a Web browser (Chrome, Firefox, Opera, Edge, etc.), but it can be any tool acting on the users behalf. These components, the client and the server, communicate by exchanging individual messages (as opposed to a stream of data, for example).
The browser is always the entity initiating the request, it is never the server - although it is possible to simulate server-initiated messages.
When a client sends a message to the server, it is known as a request and when the server send a message as an answer, it is called a response. This pair of one request + one response is known as a transaction. Once the server has answered to a request with a response, the transaction is complete and any further communication between the client and the server require a new transaction.
HTTP is stateless - a request does not know about any previous requests, by default. Statelessness means that no state is kept between two requests. This results in that all data required to process the request must be included in the request. So, if there is no state, how can, for example, e-commerce shopping baskets work? Well, even though we don't have a state, we can still have sessions, meaning that we can add extra data to messages allowing several messages to be identified as belonging to the same client.
HTTP example
A request to the server might look something like this:
GET / HTTP/1.1
Host: developer.mozilla.org
Accept-Language: fr
To which the server might respond with the following:
HTTP/1.1 200 OK
Date: Sat, 09 Oct 2010 14:28:02 GMT
Server: Apache
Last-Modified: Tue, 01 Dec 2009 20:18:22 GMT
ETag: "51142bc1-7449-479b075b2891b"
Accept-Ranges: bytes
Content-Length: 29769
Content-Type: text/html
<!DOCTYPE html... (here come the 29769 bytes of the requested web page)
The browser makes these requests when, for example, clicking on a link. You can also make the request from, for example, the command line as well as inspect the requests that the browser makes through the browser's dev tools.
Requests
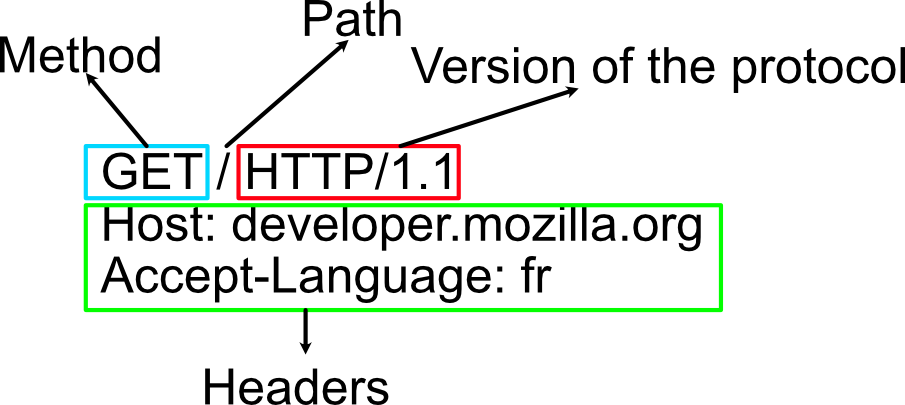
Requests consist of the following elements:
- An HTTP method that defines the operation the client wants to perform. Typically this is
GETfor fetching a resource from the server orPOSTfor posting data to the server, but more operations may be needed in other cases. - The path of the resource to fetch. Here it was simply
/, which would in this case translate to point to the host. - The version of the HTTP protocol.
- Optional headers that convey additional information for the servers.
- (For some methods, such as
POST) a body, which contains data for the server.
Notice in the image, that we are omitting all the information that is obvious from the context. For example, the protocol (http://), the domain (developer.mozilla.org), and the TCP port (here, 80). It happens, that browsers assume you are using HTTP protocol, unless you say otherwise. Further, they assume that HTTP server applications are listening on port 80 for HTTP and port 443 for HTTPS. So, should you write on the address bar http://www.tuni.fi:80 or just tuni.fi, the browser will make the same request.
Responses
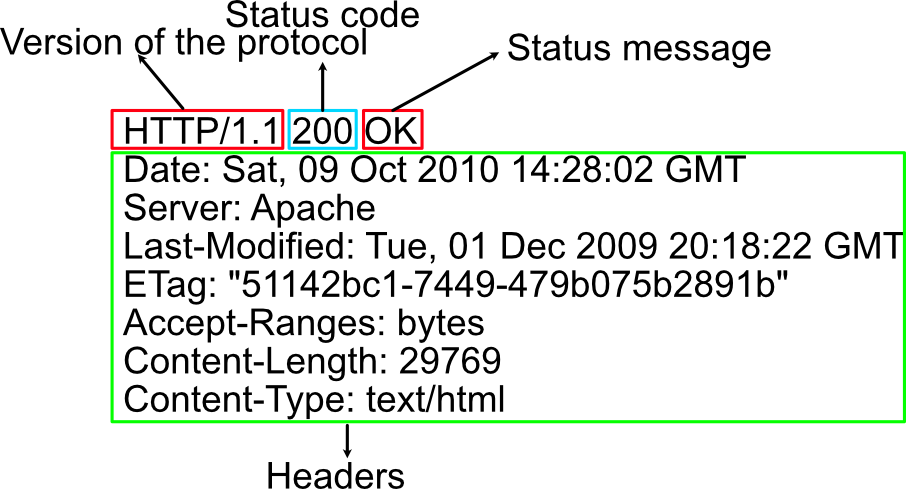
Resposes consist of the following elements:
- The version of the HTTP protocol they follow.
- A status code, indicating if the request was successful or not, and why.
- A status message, a non-authoritative short description of the status code (this is more for the benefit of humans - program code should make decisions based on the status code).
- HTTP headers, like those for requests.
- Optionally, a body containing the fetched resources (it is optional, but when we're browsing the web, this body is what we see on the browser).
So, requests and responses consist of headers and optionally a body. When browsing the web, we are mostly exposed to just the body, with the headers transmitting information for the user-agent and the server application. Further, when browsing the web, the body part is often HTML markup - a human-readable structured markup somewhat resembling XML. This HTML is further divided into a <head> and a <body>, with the <head> giving instrcutions for the browser and the <body> containing the actual information intended for the user.
A typical webbsite request might consist of first requesting the URL, for example, GET example.com, to which the server might typically be configured to respond with a file called index.html. The browser then starts reading the HTML and might come along with references to a CSS style definition file and a JavaScript file in the <head> section of the HTML document. The browser then needs to make further GET requests to obtain those files. The browser proceeds to render the markup on the screen but comes along with an <img> tag. Yet another GET request needs to be performed to obtain that image, during which the HTML document is shown rendered, only without the image. Even so, that if the dimensions of the expected image file are not specified in the HTML, the browser does not know how much empty space to leave for that image, thus causing the flow of the document to change each time an image finishes loading.
This process is roughly outlined in the chart below:
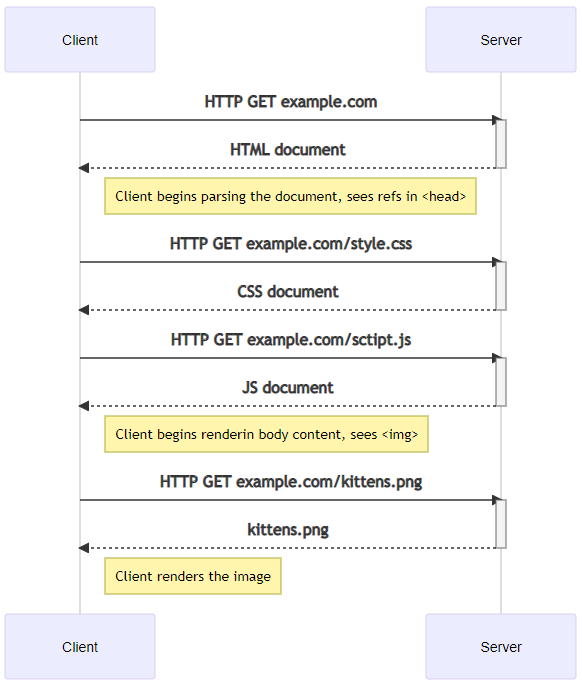
| Extra: Mozilla Developer Network - HTTP.
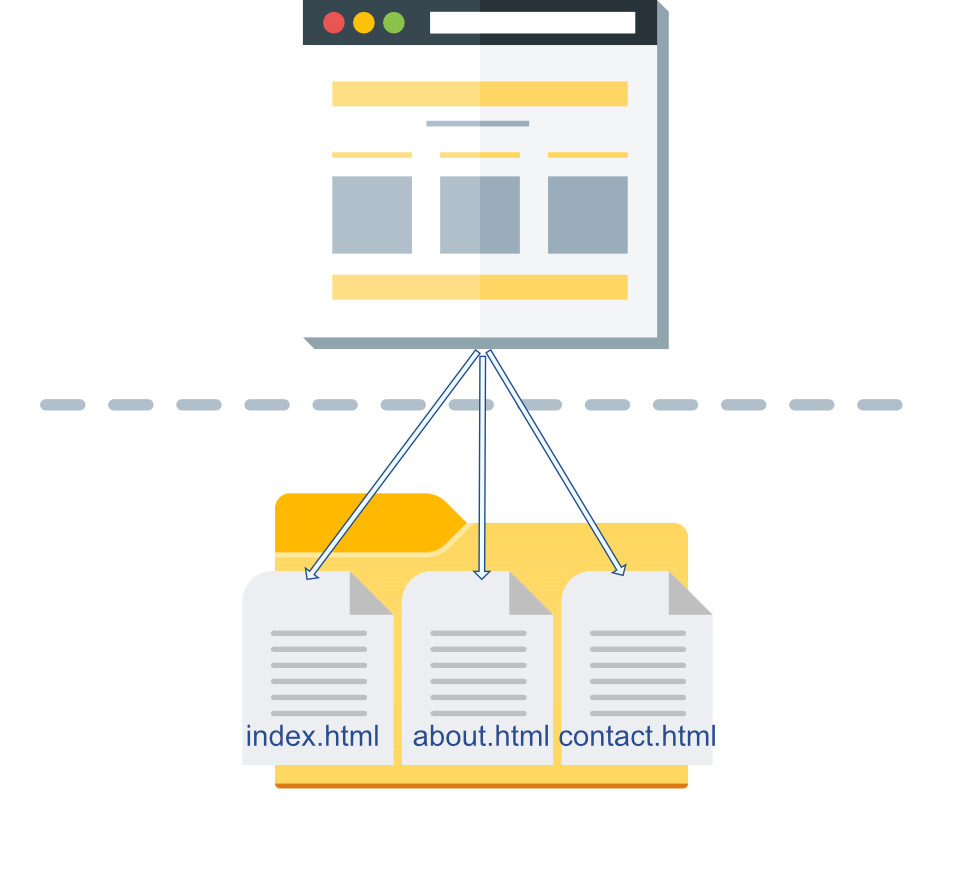
The example above is the traditional, old-school paradigm of a server-rendered website. In this scenario, the client is dumb - it receives the HTML from the server and displays it to the user. The HTTP interaction on the client side is restricted to at most clicking on a link, which then causes the browser to perform a GET request or to POST a form. If you were to view the files in the filesystem, they might look like something like this:
Mode LastWriteTime Length Name
---- ------------- ------ ----
-a---l 26.10.2021 14.13 960 about.html
-a---- 26.10.2021 14.13 120 contact.html
-a---l 26.10.2021 14.13 70 index.html
$\var\www\html>
And if you would open the index.html in a text editor (or clicked on the "view source" option in the browser) it might have looked something like this:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Welcome to my website</title>
<link rel="stylesheet" href="style.css">
<script src="script.js"></script>
</head>
<body>
<p>Here's some kittens
<img src="kittens.png" alt="Some kittens">
</p>
<p>
<a href="about.html">About us</a> |
<a href="contact.html">Contact us</a>
</p>
</body>
</html>
These are websites created using HTML. They are written in the form that is presented to the users. If some data needs to be changed, open the file in an editor and change it. This is a fast and simple tool for so-called static sites (let's call them just websites).

However, many sites are more dynamic (let's call them web applications to differentiate them from static websites). You can't write a search engine results page by hand - that needs to be done programmatically. To do that, the pages must be generated by some application. Traditionally, those applications have been created with the P programming languages: PERL, PHP, and Python, with around 80% of websites running on PHP (WordPress alone powers 40% of websites). This has lead to the creation of web frameworks (e.g., Laravel, CodeIgniter, CakePHP, etc. for PHP, Django and Flask for Python, Spring for Java, Rails for Ruby, etc.). Where static sites might link from one page to another (<a href="about.html">About us</a>), frameworks tend to handle all traffic internally. With this, I mean that a link to "about us" would be directed to, for example, example.com/about which behind the scenes ends up in the application that renders the page combining static assets, layout files, and database data. The end result in the browser is a normal HTML document, but that document does not exist in the server - it is created upon request with up-to-date data by the web application.
These web applications can do more than just show static assets. They can have user accounts; they can send email to users; they can have user-generated content, such as comments and chat messages; they can serve as online stores. These and many more things are possible with web applications.
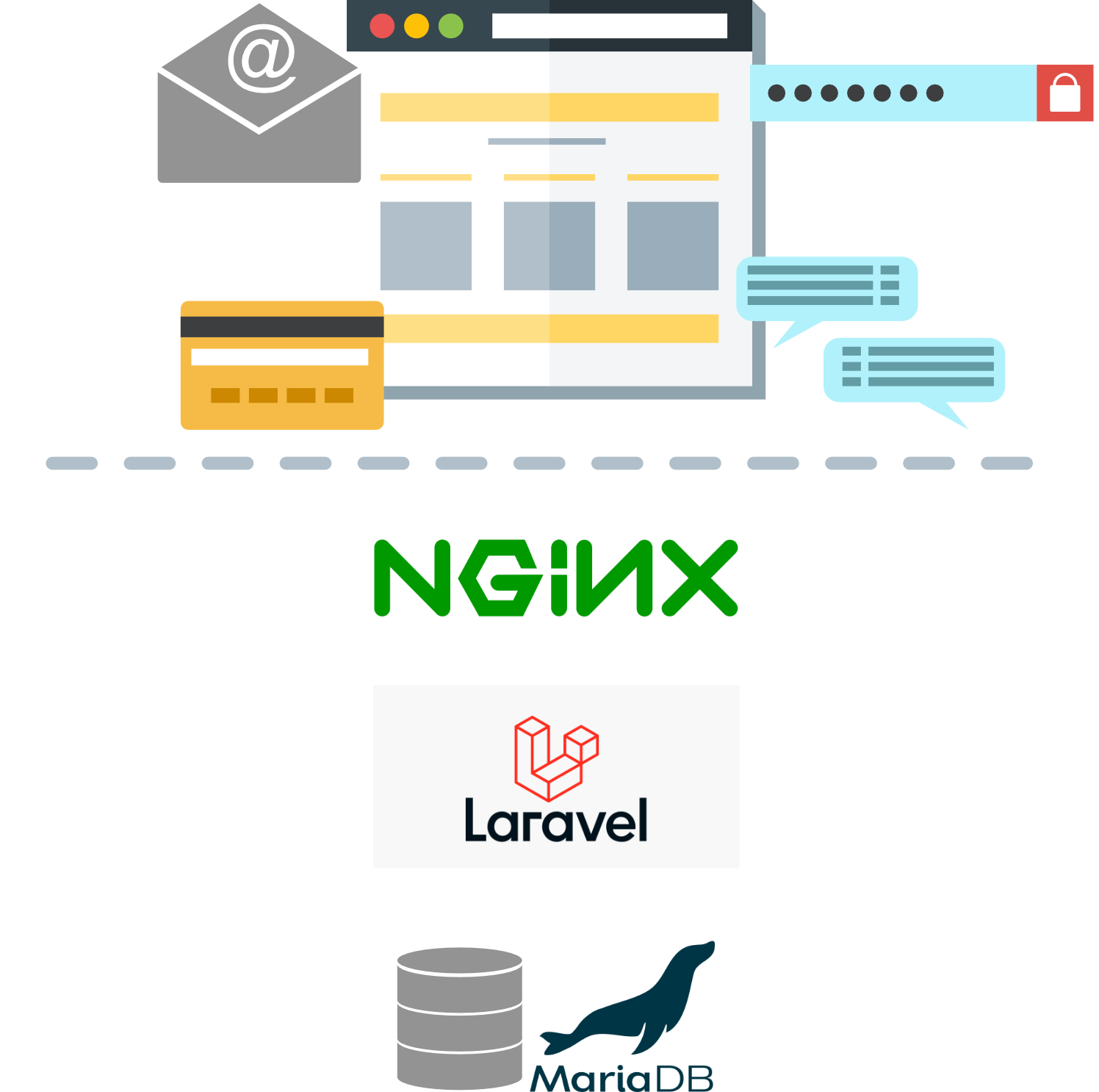
Fast-cgi and Laravel are for PHP apps. You can substitute the Laravel logo in the above figure with Gunicorn + Django for Python, Spring Boot + Spring for Java, or ASP.NET Core for C#, etc. Also, you can substitute the SQL database with NoSQL databases, such as mongoDB, or database services such as Firebase.
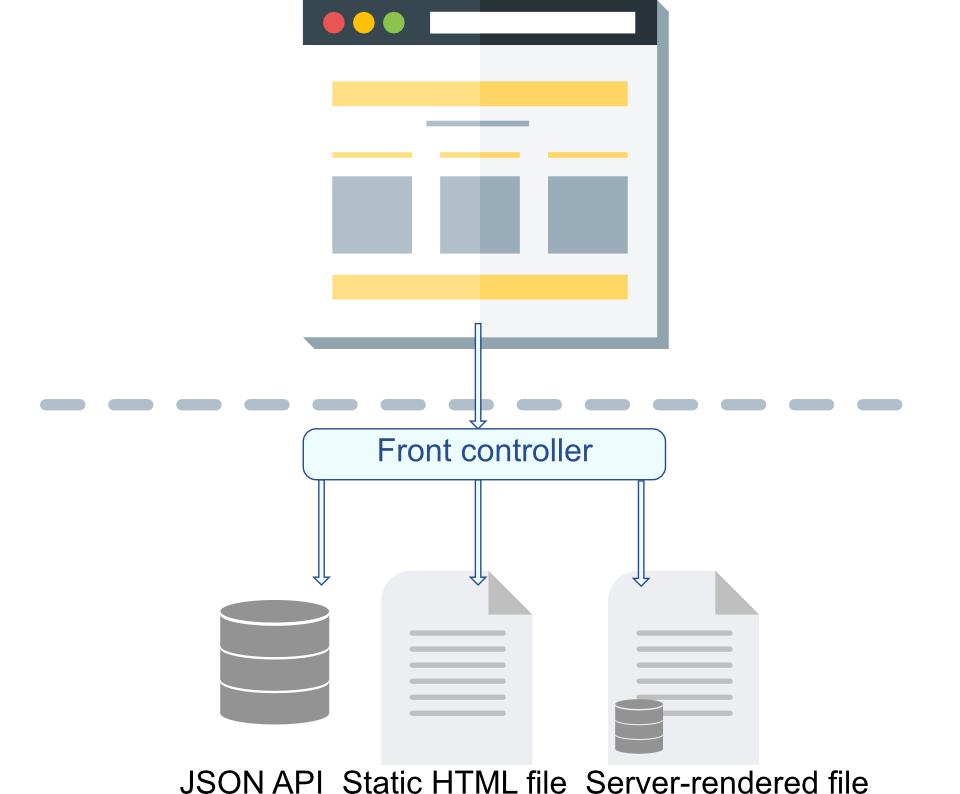
Responding to requests with HTML documents that the browser only renders is typical. This is how websites and web applications have been made for decades, and this is what the WWW was designed to do. However, web applications such as Facebook and Google Docs do not work like this. There is a lot of data going back and forth without the browser performing a full refresh once. In this paradigm, the client is smart: there is JavaScript code responsible for performing HTTP requests in the background, sending and receiving data from the server via an API, and modifying what we see on the browser window. You load the page once, and all further requests update only a portion of the page.
The backend can be very similar between these two web applications. One returns HTML to the client, while the other returns some structured data that the client inserts into the HTML document. The request handling and database operations can be identical, and the process can deviate only when returning the response to the client. Also, the user authentication is often different, but we'll return to this when we cover authentication and authorization.
Now, to differentiate these two web applications, we can talk about server-rendered web applications and web APIs. There is no need to be one or the other: many web applications, in fact, offer both. One example could be utilizing social login options, those buttons that say something like "Login with Facebook" or "Login using GitHub". There, the authentication is outsourced and will take place using an API, but the rest of the responses might still be server-rendered HTML documents or even static HTML documents. Also, the same codebase might cater to browser clients using server-rendered documents and to mobile app and IoT device using a web API. Such applications might be rather large, monolithic, and would perhaps be better maintainable split into smaller applications, but that's another topic.
For static sites and server-rendered dynamic sites, the client is usually a web browser. Today, the browser is most likely on a mobile device rather than on a computer, which requires special attention when designing the visual layout and interaction, but it's still a browser, and it transfers information visually to a human. With web APIs, the client can also be (in increasing numbers) an IoT device. Those do not require visual layouts, links, or buttons but do require well-formatted machine-readable data.
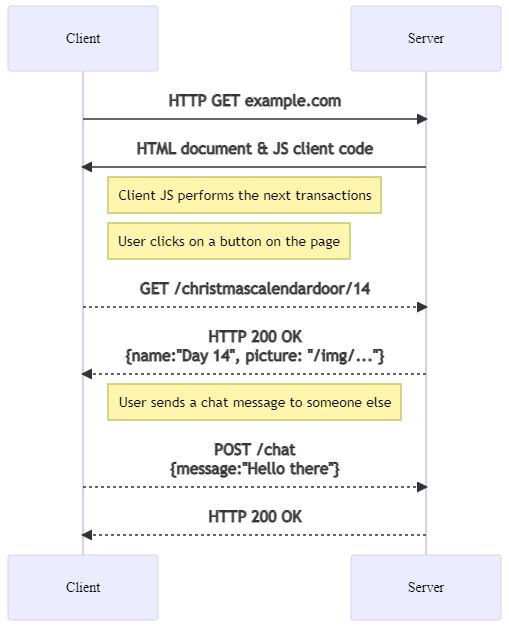
We will cover this over the span of the course, but the process might look something like in the chart below:
HTTP consists of verbs
OK, some of them are nouns, such as HEAD, but everyone talks about HTTP verbs. There are several verbs, or request methods, in HTTP. These indicate the desired action to be performed for a given resource. Although some of them differ in, for example, whether they can have a request body, it is ultimately up to the developer to respect their intended behavior. Still, each shares common characteristics: each can be safe, idempotent, or cacheable. There are nine request methods, but for the most part of web developers day-to-day work, you'll only be using five of them:
| Method | Intended behaviour/use case |
|---|---|
GET |
Request data from the server. Can include query string parameters, for example, GET /search?=Surface+Go+3 |
POST |
Submit an entity to the specified resource. |
PUT |
Replace all current representations of the target resource with the request data. |
PATCH |
Apply a partial modification to a resource with the request data. |
DELETE |
Delete a specified resource from the server. |
There are safe methods GET and HEAD: these will fetch some data and, importantly, will not have any side effects on the server. If I can delete a resource from your server with a GET request, you are doing something fundamentally wrong and dangerous. GET is the method that the browser makes when following normal links and when opening an URL.
Idempotent methods will always result in the same side effects even if executed single or multiple times. Safe methods are also idempotent, but not all idempotent methods are safe methods: idempotent methods also include PUT and DELETE, which are not safe.
GET is safe and idempotent. You can refresh the Google front page multiple times without any change in the server (except perhaps some logging and user tracking). POST is not safe, nor idempotent:
POST /chat HTTP/1.1
message=hello
POST /chat HTTP/1.1
message=hello
POST /chat HTTP/1.1
message=hello
This should result in changes in the server (i.e., not safe) as well as there being three of them (i.e., not idempotent).
DELETE is idempotent but not safe, even if the returned status code may change between requests: once you delete a specific resource, you cannot delete that same resource again.
DELETE /messages/1 HTTP/1.1 -> Returns 200 OK if the resource existed
DELETE /messages/1 HTTP/1.1 -> Returns 404 Not Found, as it just got deleted
DELETE /messages/1 HTTP/1.1 -> Returns 404 Not Found
In the browser context you are limited to just GET (links, linked resources, such as images, forms) and POST (forms), but with JavaScript you can perform all of the methods.
| Extra: There are also a few more methods. You can read more from the W3C specification.
GET vs POST
GET is used to request data from a specific resource. However, extra data can be added to the request as query string parameters, such as /path/form.php?name1=value1&name2=value2. The data after the question mark (?) is not part of the name of the requested resource but rather extra data provided for the server. For example: /path/search.php?term=javascript. The query string is visible in the address bar and in places, like the browser history, so it should only ever be used for retrieving data.

Warning
You should never pass sensitive data in the URL of a GET request.
However, in cases like a search, you should consider sticking with GET: this allows you to send the search results as a link to someone else and to bookmark it for yourself.
| Extra: Mozilla Developer Network - GET.
POST is used to submit data to be processed to a specific resource on the server:
POST /path/form.php HTTP/1.1
Host: foo.com
name1=value1&name2=value2
One (over) simplification might be that GET is like downloading and POST is like uploading. However, POSTing a form usually results in "downloading" some HTML page as well. Still, with JavaScript, you could make a web application that communicates using only DELETE requests. I advise against that.
| Extra: Mozilla Developer Network - POST.
Response codes

As said, responses have a status code indicating if the request was successful or not, and why. There are a lot of status codes or response codes making it possible to give accuare information, but generally these codes are also divided into response families:
| Response code | Response family |
|---|---|
1xx |
Informational responses, e.g., 100 Continue |
2xx |
Success responses, most common 200 OK |
3xx |
Redirect responses, e.g., 301 Moved Permanently |
4xx |
Client errors, e.g., 404 Not Found and 403 Forbidden |
5xx |
Server errors, e.g., 500 Internal Server Error |
Info
There is also an error 418 I'm a teapot where "The resulting entity-body MAY be short and stout." The server refuses the attempt to brew coffee with a teapot.
Video: Using browsers dev tools to analyze requests and responses
REST(ful)
REST is short for Representational State Transfer. It is a resource-based architectural style that relies on nouns instead of verbs, for example GET /users/{id} instead of /get-user?id={id}. REST is often used together with JavaScript clients and asynchronous transactions, but in it's self it is just an architectural style that you should be using with traditional server-rendered sites as well.
You can name your endpoints whatever you like. REST suggests you name them in a uniform, resource focused way and use the appropriate request methods. For example, DELETE /comments/7 instead of POST /delete-comments.php?comment_id=7. So, URIs point to resources or collections of resources (e.g., /comments/7 and /comments) and request methods inform what to do about them.
In Representational State Transfer (REST) the focus is on resources that can be accessed and acted upon in a standard way, rather than on method, like in RPCs.
Roy Fielding described REST in his dissertation Architectural Styles and the Design of Network-based Software Architectures.
"Anything that is important enough to be separately referenced/ modified/retrieved is a resource that has a reference. Universal Resource Identifier (URI) is the reference. They should be constructed in an intuitive (human-readable) manner and reflecting the underlying data structure."
RESTful web services
Resources are any type of data that can be pointed to with a hyperlink: images, documents, web services, etc. Data is encoded in a way that it can represent the state of the resource and resources are referenced by URIs. REST is a pattern, a way of doing things, that is not formally codified.
Multiple URIs can point to the same resource, for example:
GET /posts/{post}/comments/{comment}
GET /comments/{comment}
In REST, different representations are possible for the same resource. JSON and XML are commonly used. For example:
GET /users/1
{
id: 1,
name: 'John Doe',
occupation: 'Secret agent'
}
But even if you return server-rendered HTML files, you can (and perhaps should) still follow the RESTful routing style. REST APIs often use JSON since it offers many benefits, such as ubiquity, simplicity, readability, flexibility, etc. However, XML / plaintext / HTML, etc. are also used.
| Extra: Beautiful REST & JSON APIs by Les Hazlewood
In RPC, resources can be thought of as verbs. In REST, resources should be nouns. Broadly speaking there are two types of resources:
Collection resource: e.g., /posts/2014. These link and list multiple instance resources. They might also have their own attributes, such as first, latest, etc.
// from: http:/some-library-service/keyword/javascript
{
"keywords": ["javascript"],
"books": [
{
"href": "http://some-library-service/isbn/978-0596517748",
"isbn": "978-0596517748"
}, {
"href": "http://some-library-service/isbn/978-1933988696",
"isbn": "978-1933988696"
},
...
]
}
Instance resource: e.g., /posts/my-first-post. These resources describe one instance of something.
// from: http://some-library-service/isbn/978-0596517748
{
"title": "JavaScript: The Good Parts",
"author": "Douglas Crockford",
"published": "2008",
"isbn": "978-0596517748",
"href": "http://some-library-service/isbn/978-0596517748"
}
Statelesness
Any individual request should be understandable without the knowledge of any preceding requests. This also means that requests can be interpreted and acted upon individually, which makes parallel processing easier. All required data needs to be presented in the request itself.
Addressability
Addressability, or that every resource has a unique identifier, gives the major benefit of using resources in unforeseen ways.
Related to this, it is a good idea to version your APIs. For example http://my-cool-site.com/api/v1/some/stuff.
The future is unknown and you might need to change the API for one reason or another. Versioning enables you to leave the old behavior in place so those programs that depend on that version will not be broken.
Connectedness
The idea of connectedness is that resources link to other resources. Following links traverses the API uncovering more information and structure.
Uniform interface
All the resources share a common uniform interface. Instead of doing something (URLs as a "method") set something (URLs as "variables").
The four main constraints of uniform interface take advantage of HTTP "verbs":
| Verb / Method | Intended action |
|---|---|
GET |
fetch a resource or a collection of resources |
PUT |
create / replace resource |
DELETE |
remove a resource |
POST |
add / modify resource |
POST is not idempotent, so it can be used for partial updates. However, it is also common to break this rule and use POST for creating a resource and either PUT or PATCH to update it.
The principles of a uniform interface are:
- Identification of resources: Request identifies the resource, data could be returned in a number of formats
- Manipulation of resources through representations: If a client has the resource, it knows enough to modify or manipulate it
- Self-descriptive messages: Each message contains enough information on how to process it (what is its mime-type, etc.)
- HATEOAS: Hypermedia as the Engine of Application State
| Extra: Wikipedia has a nice article about REST.
Client-server
Separation of user interface concerns from data storage concerns improves the portability of the user interface across multiple platforms, improves the scalability by simplifying server components, and allows the components to evolve independently.
RESTful routing
Considering we have a blog with many blog posts, the server might listen to the following routes:
| Method | URI | Description |
|---|---|---|
GET |
/posts |
Get a list of all posts |
GET |
/posts/:post |
Get one specific post |
POST |
/posts |
Store a new post, data in request body (this could be also PUT) |
PATCH |
/posts/:post |
Update a specific post, data in request body (this could be also POST) |
DELETE |
/posts/:post |
Delete a specific post |
Hopefully, you are starting to some similarities here to what you have learned about databases. With databases, we have a few basic operations, called the CRUD operations. That is, Create, Read, Update, and Delete. The RESTful routes match those perfectly.
| Method | URI | CRUD operation |
|---|---|---|
GET |
/posts |
READ (SELECT * FROM post) |
GET |
/posts/:post |
READ (SELECT * FROM post WHERE id = :post) |
POST |
/posts |
CREATE (INSERT INTO post VALUES...) |
PATCH |
/posts/:post |
UPDATE (UPDATE post SET...) |
DELETE |
/posts/:post |
DELETE (DELETE FROM post WHERE id = :post) |
A modern web application might listen for these requests with something like the following pseudo-code:
route.get('/posts', 'PostController.index')
route.get('/posts/:post', 'PostController.show')
// if server-rendered, we need a form for creating new reeource
route.get('/posts/create', 'PostConrtoller.create')
route.post('/posts', 'PostController.store')
// if server-rendered, we need a form for editing existing resource
route.get('/posts/:post/edit', 'PostController.edit')
route.patch('/posts/:post', 'PostController.update')
route.delete('/posts/:post', 'PostController.delete')
The create and edit routes would return a form for creating and editing resources if the website is server-rendered. If the website is built on top of a REST API, these would not be needed, as the forms could be shown using the client code.
Here I've also introduced a new concept: a controller. Many popular web frameworks use the Model-View-Controller or MVC architecture. Let's not get too bogged down with that right now, but just a sneak-peek, let's look at what that PostController might look like:
class PostController {
function index() {
posts = Post::all()
return view('post.index', posts)
}
function show(postId) {
post = Post::find(postId)
return view('post.show', post)
}
function create() {
return view('post.create')
}
function store(data) {
post = Post::create(data)
return view('post.show', post)
}
function edit(postId) {
return view('post.edit', postId)
}
function update(data, postId) {
post = Post::find(postId)
post->update(data)
return view('post.show', post)
}
function delete(postId) {
post = Post::find(postId)
post->destroy()
return redirect(index)
}
}
Here you might spot the different components playing nicely together: the controller handles things in high level, the model takes care of persisting the data, and the view renders some template with the decired data. The responsibilities are nicely divided - the controller does not know or care how model persists data. Is it a database or a flat file? The controller does not care. And the view does not care about anything else than just receiving data.
Statelessness
REST requires statelessness, and for example; the HTTP protocol fulfills this requirement.
One transaction = one request + one response
Transactions are individual. Nothing ties two transactions together. Further, they are stateless - preceding events or interactions are not remembered! Each request from the client to server must contain all the information necessary to understand the request. The requests cannot take advantage of any stored context on the server. Session state is kept entirely on the client.
Let's say you have a button on a website and you wonder how you can call a method on the server when the button is clicked. In HTTP you can't. The server application has stopped responding to your request and that execution cannot be reached anymore. Only thing you can do is to make another request.
Statelessness improves visibility, reliability, and scalability. Visibility is improved since a single request shows the full nature of the request. Reliability is improved since it makes it easier to recover from partial failures. And scalability is improved since resources can be quickly freed because of no state between requests. Further, implementation is simplified, as the server does not have to manage resource usage across requests.
On the other hand, statelessness may decrease network performance, as it increases the repetitive data sent in a series of requests. It also reduces the server's control over consistent application behavior - the application is dependent on the correct implementation of semantics across multiple client versions.
Having said all this, applications often need to use states internally. For example, a shopping basket needs to hold items when the page changes and login details are not sent for each page load. The browser does not send an identifier automatically - this needs to be taken into account when creating applications.
To tie two requests together as a session, we need an identifier included in both requests. Something that can be used to pick those two requests out of all incoming requests and say these two requests are coming from the same user. There are several ways to do this. Some are better than others. We could add an identifier manually. Perhaps a query string parameter, such as index.php?session=XYZ123B? Or a hidden input field in forms, such as <input type="hidden" name="session" value="XYZ123B">? This would be needed for each request. So, not very convenient and not very secure. The first example used query string parameters that are sent using a normal GET requests. This means that the value is visible on the address bar and in the network traffic. An attacker would only need to see the value and append it to their request to be able to impersonate as the victim. The latter example could be done using POST requests, as forms are able to perform both GET and POST requests. In a POST request, the value would not be visible on the address bar but rather travel in the request body (which is not possible with GET requests). Still, this would limit us to only make POST requests, which goes against the REST principles. Not to mention the need to turn every link into a form.
Luckily, the issue has been resolved using cookies. But before we can properly understand cookies, we must first take a look at HTTP headers. And we'll do that by first writing our own server.
Creating our own server
Let's now start putting the theory into practice by creating our very own simple server in Node.js. Albeit simple, this server will still listen for incoming requests and respond to them as a good server should.
// We need to import the http to deal with HTTP
var http = require('http');
//create a server object:
http.createServer(function (req, res) {
res.writeHead(200, {'Content-Type': 'text/plain'}); //these are the headers
res.write('Hello World!'); //write a response to the client
res.end(); //end the response
}).listen(8080); //the server object listens on port 8080
| Extra: Check out more options in Node.js website.
Notice, how we are instructing our server to listen on the port 8080 with the method listen(). As you might know, if an ip address is like the street address of an appartment building, the a port is like one appartment in that building. If our server is listening on this port, it will only respond to requests coming to that port. In fact, it will not become aware of any other requests to any other ports, even if they come to the same computer. Further, once our server starts to listen to a port, that port becomes occupied. We can not have multiple instances of this server listening on the same port. We can, however, run multiple instances of this server, if we change the port for each of them. Remember also, that browsers will, by default, add port 80 to all requests, unless instructed otherwise. To reach this server on the localhost, we would need to write to the browser address bar localhost:8080.
In the example above, our createServer method receives two parameters, a request and a response - so, everything needed to handle one transaction. As a refresher, a request consists of:
- a request-line (e.g.,
POST /newsletter HTTP/1.1), - optional headers (e.g.,
Content-Type: application/x-www-form-urlencoded), and - optional body content (e.g.,
email=john.doe@example.com&acceptTerms=true).
And a response, similarly, consists of:
- a status-line (e.g.,
HTTP/1.1 200 OK), - optional headers (e.g.,
Content-Type: text/html), and - optional body content (e.g.,
<html><body><h1>Succesfully enrolled...).
The exact specifications can be read at the RFC 2616 spec, but since we will use these for all of our communication, you should get very familiar with them during this course.
We are also writing a response header using the res.writeHead() method. HTTP headers are used in transactions to pass additional data. They consist of a name and value pair, separated by a colon. A Node.js example of setting HTTP header named Content-type to value text/plain for a response is as follows:
res.setHeader('Content-type', 'text/plain');
These headers can describe the request body, add extra information, such as authentication information, tie requests into sessions, specify the charset used, etc. The content-type MIME type representation header is used to indicate the original media type of the resource prior to any content encoding applied for sending. If, for example, we are returning a pdf file or HTML, we need to inform the client about it.
One special MIME type you will often need to use is multipart/form-data, which is required when you try to upload files from a client to the server. But don't worry about these too much just yet. For now, it should be enough to remember that if a REST API returns a JSON response (as they often do), you should use
res.setHeader('Content-type', 'application/json');
...and if your traditional, server-side rendering application returns HTML documents, you should use
res.setHeader('Content-type', 'text/html; charset=UTF-8');
With Node.js, the headers object for the incoming request can be read with:
const { headers } = request;
What are the curly braces for?
In the line const { headers } = request; we are using a technique called object destructuring to access the headers part of the request object. We could also just write const headers = request.headers;
The Content-type header can then be read with:
const contentType = headers['content-type'];
In Node.js, all header names are set to lower-case to simplify parsing headers.
Cookies
Cookies are HTTP headers. They are also a common way to handle states. The HTTP cookie (web cookie, browser cookie) is a small piece of data, that the server sends to the user's web browser. The browser may store it and send it back with the next request to the same server. Typically, it is used to tell if two requests came from the same browser - to keep a user logged in, for example. Cookie remembers stateful information for the stateless HTTP protocol.
| Extra: Mozilla Developer Network - Cookies
Character encoding
HTML code is just normal text in a file. Usually, these files have the .html extension, but as we all know, the extension does not dictate the content. As with all text files, the characters we type must be turned into binary numbers for storing. There are several encodings, that may be used, for example:
| Encoding | Description |
|---|---|
ASCII |
The OG of encodings. Letters, characters, some symbols. All together 127 characters. |
ISO/IEC-8859-1(Latin1) |
Western characters based on the Arabic script |
ISO/IEC-8859-15 |
Modified ISO-8859-1 to support Finnish, French, and Estonian |
Windows-1252 |
Superset of ISO-8859-1, with additional symbols |
Unicode |
Contains characters for most living languages and scripts in the world |
Unicode
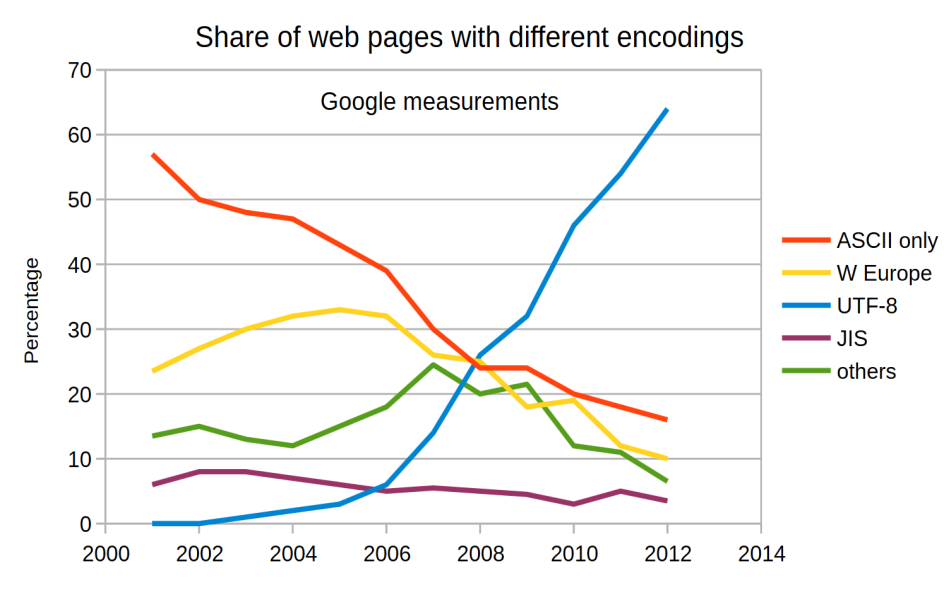
Unicode can be implemented using different encodings. The UTF-8 is used on web pages nowadays.
UTF-8 uses variable length to save characters and symbols. It is capable of encoding over 1 million characters, and it is backward-compatible with ASCII: the first 127 characters are encoded with the same codes as in ASCII.
Character escapes (HTML entities)
HTML entities are a way of representing characters when, for example, the symbol is not available, a character conflicts with the syntax, a character is invisible or ambiguous, or when information is transferred using ASCII encoding.
Escapes provide a way of representing entities using only ASCII text: &entity-name; or &#entity-number;.
| Entity | &entity-name; | &entity-number; |
|---|---|---|
| < | < | < |
| > | > | > |
| & | & | & |
| " | " | " |
| ' | ' | ' |
| no-break space | | < |
| ä | ä | ä |
| ö | ö | Ö |
| Ö | Ö | ö |
Defining a HTML form
Forms are the only way of performing POST requests from the browser.
Attribute action specifies the form handler. Form handler runs on a server, written, for example, with PHP, Perl, etc. Attribute method specifies how the data is sent.
<form action="form-handler" method="get"|"post">
[input widget]*
{submit button}
</form>
A simple sample form could look something like this:
<form action="contact.php" method="post">
<div>
<label for="name">Name:</label>
<input type="text" name="name" id="name" />
</div>
<div>
<label for="message">Message:</label>
<textarea name="message" id="message" rows="6" cols="20"></textarea>
</div>
<div>
<input type="button" name="submit" value="Submit form" />
</div>
</form>
Which would look like this in the browser (normally, we would use CSS to style it to look nicer):
Method GET
<form action="form-handler url" method="GET">
The browser sends a request to the server program. The input data from the form is attached to the address. After a question mark (?), the field name and value pairs are encoded so that the name and value are connected with the equal sign (=) and the pairs are separated from each other with an ampersand (&).
GET is used if it does not matter that the values are visible. Search engines often use the get-method. It gives a possibility to save the query and send it to other users. Queries can be sent even without the form.
Method POST
<form action="form-handler url" method="POST">
The browser sends a request to the server program. The input data is sent in the HTTP-call in its own field. The data is hidden from the user and other onlookers.
However, also with the POST method, the data is open, as in not encrypted, and a third party is capable of reading the sent data. This includes also the password fields.
If the data is sensitive, the transfer between the browser and the server should be done using the SSL-encrypted HTTPS protocol.
Synchronous communication
Traditionally, when the user does something, for example, clicks a link, a whole new page is loaded. Would this work with, for example, webchats if after every message you would have to reload the whole page? It does not make sense to load the whole page if only a small part of it needs to be updated. It just wastes time and bandwidth.
Jesse James Garret came up with the idea of Ajax (Asynchronous Javascript And XML) based on some technology Microsoft built in the late 90s. In essence, it allows the browser to send and receive data without loading the whole page. The major benefits of this are that the user can still use the page whilst data is being exchanged and that we can update only parts of the page rather than the whole page.
AJAX is discussed in more detail in a later lecture.
HTTPS
HTTP is not encrypted. Data sent over plain HTTP can easily be eavesdropped on. This is especially true on open Wi-Fi networks, such as cafeterias, shopping malls, etc.
HTTPS refers to HTTP Secure, which is HTTP over TLS/SSL so it is encrypted. For most web applications switching from HTTP to HTTPS does not require any code modification. Mixing HTTP and HTTPS is a potential security risk and many browsers will give a warning if it is attempted.
In the past, HTTPS certificates were expensive, but now such a certificate can be acquired for free, thanks to let's encrypt.
Summary
In this chapter, we covered how HTTP transactions are formed and conducted. We explored REST which is just a convention of naming things in a certain way and doing things in a certain way. We booted up our first Node.js server and are ready to receive GET and POST requests. POST requests can be made in the browser by using forms. One really important concept to understand right now is statelessness, as it forces us to worry about data persistence and authentication.
Ask yourself
- What is the connection between the HTTP verbs and CRUD operations?
- What is the point of a routing file?
- What issues are we trying to solve by using Unicode character encoding?
- Can you think of some issues that come from statelessness?